Data Quality (DQ) has been around for years. Till a few years ago a lot of companies did not really see the need to invest in it. This has now changed. Companies start to realize that better data means better use cases. DQ lays better foundations for making data-driven decisions, setting up management dashboards, and making use of ML applications.
But why did it take so long to start investing in data quality?
Why isn’t data quality sexy?
Hearing the term Data Quality Management (DQM), likely, everyone working in data directly has some associations in mind. Rarely they are “fast”, “easy”, “straight-forward” or “elegant”. Especially in companies with lots of data and data-based solutions, the management of DQ is, first, connected to highly time-consuming a nd intense processes. Second, it is often addressed with huge DQ tools that may or may not fit the requirements of all stakeholders and use cases. On top, a lot of tools do not only address the topic of DQ but are overloaded with other functionalities and therefore quite expensive.
This comes along with long lists of Data Quality rules, excessive monitoring of the related quality results, and a huge need for regular adaptations of thresholds for any change in requirements. The result is an inert solution that gets adapted slowly and cannot keep up with the speed of data departments, who are rich in ideas for new data-driven solutions like management dashboards, monitoring of production processes, and machine learning (ML) use cases.
So, you see: Data Quality Management is not sexy! Setting up a DQM system that fits the company’s needs, fulfilling all requirements and regulations while being handy and lean in the related processes is no easy task!
What is a comprehensive DQM?
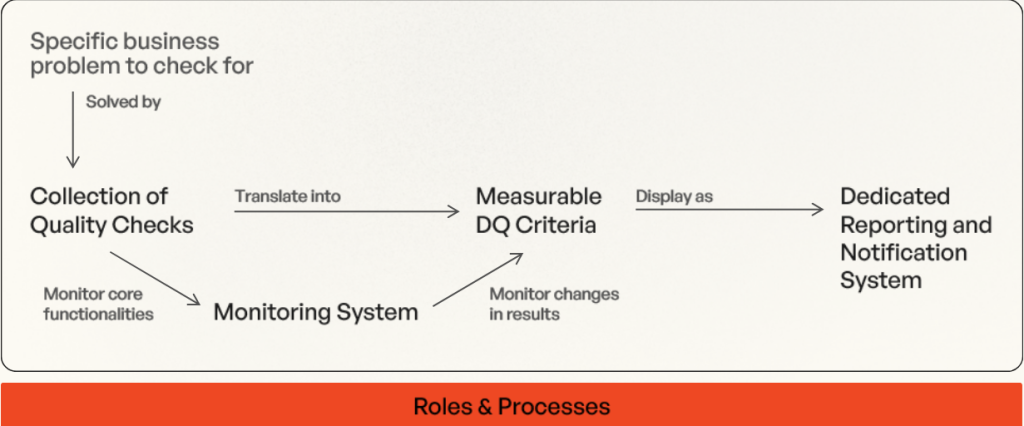
Looking at a DQM (derived from data governance policies) from a high-level perspective one would expect the following parts:
- Collections of quality checks that solve one specific business problem that consists of one or multiple quality requirement(s). Every quality check has exactly one functionality and can be completely rule-based or based on statistical know-how.
- Measurable DQ criteria which are the translation of quality checks and their collections into key figures. Making quality measurable with DQ metrics shows the extent by which the DQ meets the expectations and requirements, and allows for comparability of different data sources as well as for data-driven reporting.
- A dedicated reporting and notification system on the results of quality checks that ensures the reporting of detected quality issues the moment they come up. Additionally, this allows for a scheduled overview of the current DQ of the data sources of interest.
- Monitoring the core functionalities and the changes in the results of the quality checks facilitates the detection of unexpected changes in quality of the data in comparison to the past. Anomalies or other unexpected data patterns like data drifts might show up and can influence the accuracy of the DQM system.
- Processes and responsibilities that support the management of the detection and mitigation of DQ issues. Detected issues need to be prioritized and routed to the right people for the development of mitigation strategies and actions.
How can ML empower DQM?
Machine learning is a methodology that can support in situations where data becomes cluttered or difficult to be judged without dedicated business know-how. It helps to reveal patterns in the data that were not obvious before or not even visible at all. In DQM ML can help to deal with the detection and mitigation of quality issues and the complexity of administration.
Having a look at the DQM process (we recommend you to read the “Guidelines to implement a modular framework for Data Quality Management” by CBTW) there are different points where ML can be exploited in a useful way.
ML-enhanced DQM
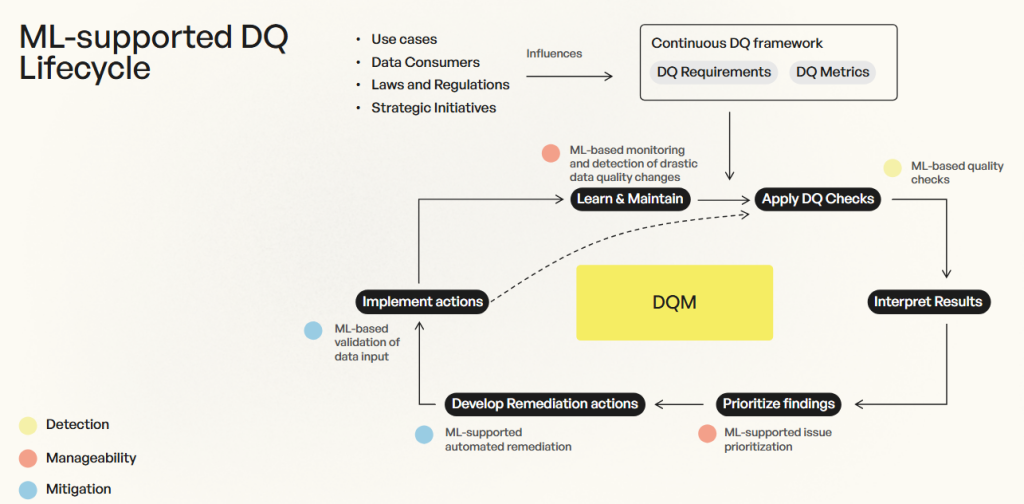
Using ML-based quality checks
The first and probably most obvious entry point for ML is the usage of ML-based quality checks. Quality checks can be very simple rules like “Is the proportion of missing values below 90%?”, “Is the data type of a specific column a string value?” or “Are the values of a specific column between 0 and 10?”.
But if you want to check for more advanced criteria like e.g. the distribution of the data in a specific column you might already want to use statistical tests to check this on your data. From there it’s not far to making use of ML to e.g. identify unexpected values in your data via anomaly detection or detect spelling mistakes in addresses or free text fields with natural language processing (NLP) technics.
Using machine learning for the detection of DQ issues allows to automate checks and the detection of DQ issues that otherwise would have needed a lot of domain knowledge and an expert assessment.
Leveraging ML-based prioritization
Using ML to prioritize the detected quality issues and manage the resources for the mitigation processes can make these complicated tasks a lot easier. Especially when it is not clear which impact the specific findings have and how they can be rated for prioritization.
Supporting this with data and using ML models like predictive modelling or recommendation engines for actionable recommendations, planning and scheduling is another method to integrate ML into the DQM process.
Especially in situations with restricted resources and multiple influenced use cases utilizing ML to analyze, prioritize and route findings to the right people becomes extremely valuable.
Using ML-based quality issues mitigation
Not all detected quality problems are easy to mitigate. This depends on multiple dimensions like data type, data source access, and the amount of domain knowledge needed. Supporting the mitigation of the detected quality issues with ML can be performed in multiple ways.
The most effective way to handle DQ problems is to prevent them altogether and fix the issues at their source. During data input, it might be possible to utilize comparisons to existing data or NLP models to fix spelling mistakes or semantical problems. Using ML models for cleansing to perform automated correction in the database can help when you do not have source access.
The mitigation of data quality issues can be very time-consuming for domain experts when a lot of domain knowledge is needed. Machine learning can help here to automate easier mitigation tasks, address problems at source or solve complex contexts.
Applying an ML-based monitoring system
In situations with multiple data sources and many sophisticated DQ checks, the number of thresholds to test against quickly becomes complex and hard to handle. With only 10 data sources and 10 different checks with unique thresholds, you reach 100 different values that want to be controlled over time. Using a monitoring system based on ML to handle anomalies, outliers and data drifts can be a game changer.
Exploiting ML methods has the potential to greatly support human efforts to deal with the complexity of monitoring huge amounts of thresholds and potential drifts in the quality metrics. Thus, it might enable easier handling of a clattered DQM systems and increase transparency for all users.
Sounds good, but overwhelming?
The good thing is: We see a Data Quality Management system as a very modular solution. You can start small and scale later on! Defining your first checks with or without the help of ML can be achieved fast and can be extended easily at another time. But: Before you start developing, don’t forget to set up requirements, quality metrics and supporting processes that allow for adaptations over time. This is the strong foundation for every well-designed and sexy DQM.
Automated Quality Assurance solution for Publicis Media.
Guidelines to implement a modular framework for Data Quality Management.